需求来了
故事的开始,是我同事问我的一个问题。
大概在 2024 年 12 月底,他问我:能不能把 FedEx 的分区邮编 PDF 转成 Excel?
我第一反应是:你用 WPS 转一下不就好了?
他说:我和你说不清楚,你自己看这个文件。
然后他把文件发给我,又给我看了看他最后需要的格式。我打开一看就明白了
这是分区表pdf
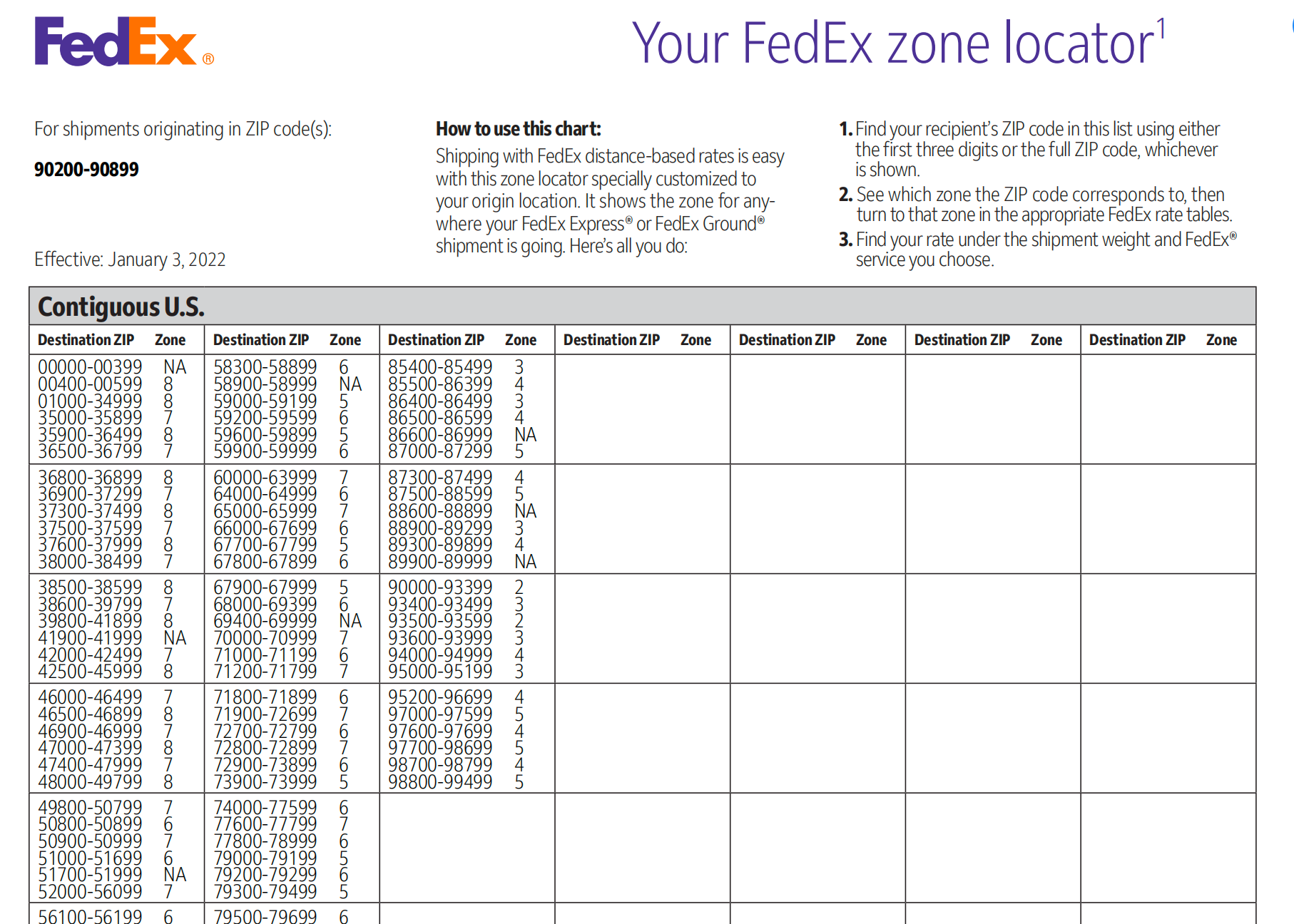 这是他需要转换的模版
这是他需要转换的模版
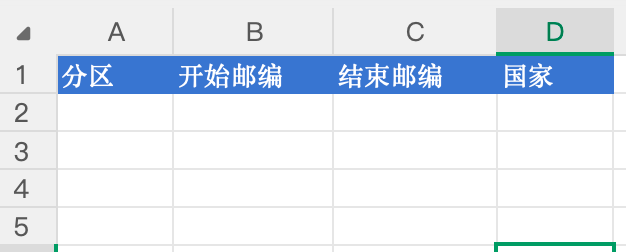
不是「整份 PDF 转成一张表」那种简单需求,而是要从一份结构复杂、排版不统一的 PDF 里,按他指定的规则把数据挑出来、整理成固定格式的表格。在 AI 来临之前,这种需求要么靠手工一点点抠,要么就得写脚本或找外包,没有「点一下就能好」的通用办法。
那一刻我意识到,复杂 PDF 里的数据提取,可能真的是一个有价值的方向。不然大家就只能继续手工做了。
我想做个 Agent!
接着我就开始想:怎么才能让 AI 自己去读 PDF,自己去理解里面的内容,自己根据用户的需求做提取,自己再把数据写进 Excel?
答案很快就冒出来了:做个 Agent。
我得做一个 Agent。这个 Agent 能自己思考、自己调用工具、自己做规划——你给它 PDF 和需求,它自己拆步骤、读表、解析、填表。那时候 Agent 的 ReAct 模式特别火,大家张口闭口都是「让 LLM 自己决定下一步调用什么工具」。现在好像没什么人再天天提 ReAct 了,但当时我觉得这就是正解。
于是开始动手。调研技术方案,选型选了 LangGraph 来做。框架搭起来,工具链接上,心想这下总该能跑通了吧。
做着做着就发现:怎么我的 AI 这么笨?
它为什么自己不会调用工具?它为什么「说做了」但根本没做?它规划出来的步骤,为什么没有一个是对的?简而言之,全是问题。那段时间我每天都在和「它不该这样啊」较劲,改 prompt、改图结构、改工具接口,效果起起伏伏,离「真的能稳定跑完一个任务」总是差一截。
中间还有一段时间,我一度觉得「Agent 自动生成工作流」才是解决这个场景的终极形态——让 AI 先理解用户需求,再自动拼出一个工作流,甚至想过要不要做一个更大的「Agent 生成工作流」的产品。但后来掂量了一下自己的实力,还是放弃了。再后来市面上确实出现了类似思路的产品,比如 Refly.AI,不过那都是很后面的事了。
就这样一直磨,磨到了 2025 年 7 月。
可能是因为模型能力上来了,也可能是我做的智能路由终于起了效果,某一天开始,我的 Agent 忽然有种「长了脑子」的感觉:能正常规划任务、会按步骤调用工具、报错也能按预期处理。我当时简直觉得,我距离颠覆这个场景只差一步了。
但哪有这么简单。
重新思考
为了让 Agent「自己思考、自己规划、自己执行」,完成一个看起来很简单的动作,前前后后可能要经过十几个步骤:理解指令、规划任务、选择工具、调用工具、解析结果、更新记忆、再规划下一步……每一步都有失败的概率。哪怕每一步的成功率听起来还不错,全部串起来之后,真正「一次性跑完」的成功率会变得非常低。
更要命的是时间。
本来只是一个很标准、很简单的提取任务,如果完全交给 Agent 去「思考 + 规划 + 执行」,一轮下来往往要一分多钟。作为产品经理,我很清楚这种体验有多糟糕——用户不会因为你用了什么很聪明的agent编排而感动,他们只会觉得「这东西又慢又不稳」。
我意识到,我一开始明明只是想解决一个很具体的场景,却在过程中被「想做一个很厉害的 Agent」这件事带偏了。
这个场景本身其实非常标准化。竞争对手的速度之所以那么快,很大概率是因为他们并没有采用复杂的 Agent 架构,而是老老实实把流程拍扁:该写死的就写死,该前置的问题就前置问清楚。是我自己在这个过程中,想「颠覆」想太多了。
于是我开始反过来想:如果不追求「什么都让 Agent 来决定」,只在真正需要 AI 的地方用 AI,会不会反而更好?
答案是,会好很多。
我把整个产品重新拆了一遍,把原本那种多轮对话、自动规划的复杂流程,收缩成了一条简单、清晰的链路:用户上传文件 → 用户填写表头和提示词 → 点击转换 → 获得结果。中间没有多余的「智能交互」,只有一条笔直的通道。
真正需要 AI 的地方只有一个:结合提示词和表头,理解 PDF,并按用户的要求提取数据。
但因为有提示词的加入,产品又在一个可控的范围内,给了用户足够的自主权。用户可以让某些字段变成计算字段,可以要求金额字段必须带币种,可以让系统自动把文件名附带到每一行记录里……类似这种「小小的自由度」,在一个高度标准化的流程里,反而会显得很有力量。
当我把这些东西都拍扁、收紧、固化下来之后,再回头看那个 Agent 版本,会有一种很明显的对比:前者是「为了炫而复杂」,后者是「为了完成任务而简单」。
更重要的是,体验真的不一样了。
完成一个任务的时间,被我从一分钟多压到了差不多十秒左右。而且因为整体流程是高度结构化的,后台可以做并发调用,用户就算一次性上传很多很多发票,提取时间也不会被线性拉长。
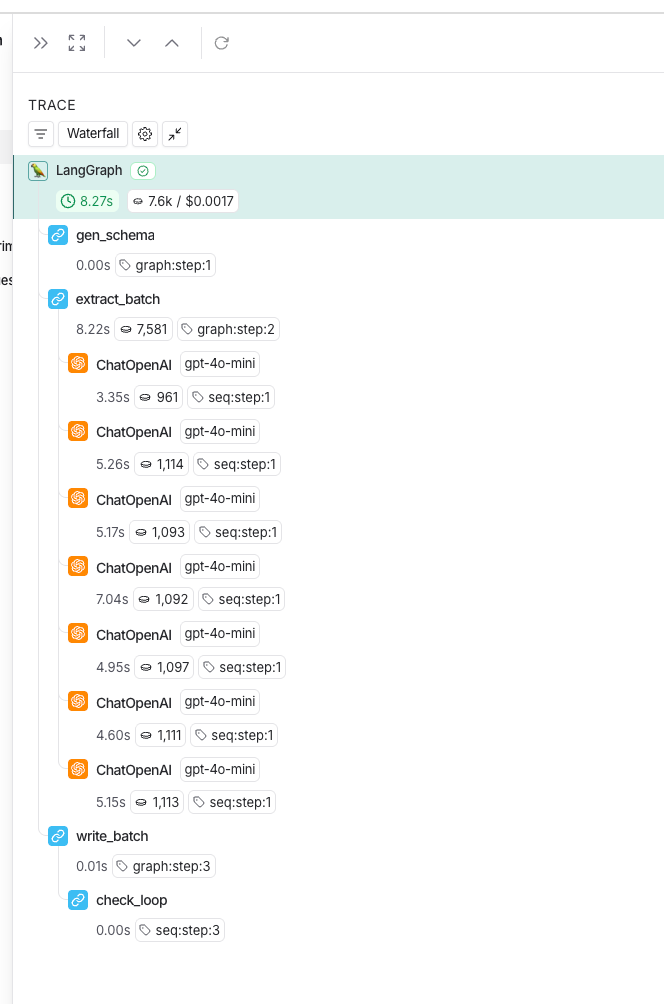
做到这里的时候,我觉得:差不多是时候上线了。
冷启动真是太难了
产品上线之后,新的问题马上摆在面前:用户从哪儿来?
这次的产品和 Figma 插件不一样。插件上架在市场里,多少会有一点「自来水」流量;transez.ai 作为一个独立网站,上线完就是一片寂静。没有流量入口,就意味着没有任何人会自然发现它——必须主动去找用户。
我当时盘了一下能做的事情,大概有三条路:
- 去 Fiverr 和 Upwork 上找那种专门帮人做数据录入的自由职业者,让他们来尝试用产品,看能不能从他们那里找到高频、刚需的使用场景。
- 做一些免费的、和 PDF 相关的小工具,通过工具吸引搜索流量,再把人导进主产品里。
- 像之前一样,在 Reddit 上发帖,去相关社区讲这个产品的故事和场景。
现在回头看,其实最应该用力做的是第三条——在 Reddit 上长期输出内容和案例。但当时我对 Reddit 的理解还不够深,不太会在那个语境里好好讲故事、建立信任。
那段时间,我最后选的是第二条路:做免费的 PDF 小工具。
事实证明,这条路「有用,但不够」。免费的工具确实带来了一些用户,也有人顺着工具进到了产品里,但数量实在太少,而且几乎没有付费用户。更关键的是,我当时把希望押在了搜索引擎流量上,对关键词这件事情异常执着——总想着只要 SEO 撑起来,问题就解决了一半。
这个执着其实是有依据的。我心里有一个假设:大部分人不会搜索「extract data from pdf to excel」这么长的词,而是会直接搜「pdf to excel」。这意味着,他们极大概率会进到 ilovepdf 这种网站——而不是一个专门做数据提取的工具。
后来有一个真实用户的使用轨迹几乎印证了这个猜想:他上传的文件名里,居然直接带着「ilovepdf」。这基本可以说明,他先用过 ilovepdf,但没解决问题,才又继续寻找别的工具。这也从侧面说明,市面上那种「一比一格式转换」的 PDF to Excel,并不能覆盖「数据提取」这个需求。
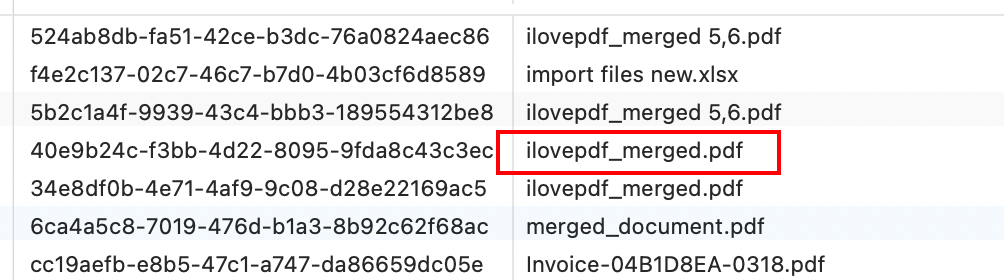
那一刻我真的很兴奋,觉得只要能把这部分精准用户捞出来,一定会有人为这个能力付费。
然而,增长并没有我想象得那么简单。
我写了一些 SEO 文章,也做了一整套围绕 PDF 的免费小工具,结果是:流量有,但一直是「少少的」。到今天为止,仍然是少少的。冷启动这件事,没有被某一篇爆款文章或者某一个小工具瞬间解决,它更像是一条漫长、磨人的小路。
方向转换
网站没什么流量的时候,我女朋友给了我一个很实际的建议:要不要在 Google Sheets 里做一个插件?
坦白说,这个想法我很早就有。但当时有两个卡点:
- 一个是「做网站」的执念。我总觉得,真正的产品应该是一个独立的网站,而不是「依附」在某个宿主里的小插件。
- 另一个是「想做厉害的 Agent」这件事。一个脚踏实地的 Sheets 插件,看起来一点都不「颠覆」,也不够酷。
现在回头看,这两个卡点多少都有点自负的成分在里面。
后来事实也确实狠狠打了我一巴掌。
还没等我把 Sheets 插件做到特别成熟,Claude 和 OpenAI 先后出了 Excel / Sheets 方向的插件和原生能力——而且是那种「模型厂降维打击」级别的。那一刻的感受,说不绝望是假的:你意识到,很多你辛辛苦苦构思出来的东西,人家在基础设施层面一发版本,就可以覆盖掉 80%。
理性地讲,这并不意味着这个产品完全没必要做下去。Google Sheets 里的场景依然是真实存在的,很多公司也确实不会第一时间把工作流全部交给通用大模型。但这也意味着,我不会再像一开始那样,把所有精力都砸在「做一个很大的、很通用的 PDF Agent 产品」这件事上。
后面这个项目,我还是会以 Google Sheets 插件的形态继续往前走,只是节奏会更稳、更慢一些——不再幻想把它做成一个「颠覆一切」的超级产品,而是接受它作为一个在特定场景里很好用的小工具。
经验和教训
回过头看 transez.ai 这一圈下来,有几条经验和教训,我现在会牢牢记在脑子里:
经验 1:在不同场景下,Agent / Workflow / RPA / 人工,各有各的胜场。
妄想用 Agent 去覆盖一切业务场景,是很片面的。像 transez.ai 这种高度标准化的任务,固定流程 + 适度的 AI 能力,往往比一个「什么都想自己决定」的 Agent 更稳、更快。
经验 2:不是有业务痛点,就一定适合做成独立产品。
有痛点 ≠ 有产品机会。尤其是在模型厂的节奏下,降维打击来的速度,可能会比你预期的快 10 倍。很多你觉得可以做三年的东西,可能一年内就会变成基础能力。
经验 3:在启动之前,先把冷启动策略想清楚。
最好在产品还没完全成型的时候,就先去 Reddit 发帖、先去和潜在用户聊聊。找到那些真的有付费意愿的人,甚至应该排在「把产品做完」之前。没有真实用户,再漂亮的架构和功能,最后都只能停留在自嗨层面。
经验 4:快且高频,比「憋一个大招」重要得多。
这里的「快」不只是指响应时间要快,更包括从想法到上线要快、内容发布要高频、功能更新要高频。世界变化太快,不会容许你慢慢憋一个大的——大概率结果是拉了一坨大的。持续、小步、快频率地向前,才是正确的模式。
经验 5:承认自己不是天才,ego 太大只会害了你。
很多走弯路,都是从「我应该能做出一个更牛的东西」开始的。承认自己不是天才,接受「日拱一卒」「做有用的东西」,往往比执着于颠覆更健康。吾日三省吾身:这是我想要还是用户想要,这是我觉得很酷还是用户觉得很爽,真的要这么复杂吗,有没有更简单的方法。
经验 6:AI 不能帮你找到真实用户。
几乎所有「方向上的调整」和「技术方案上的调整」,AI 都会赞同你、甚至帮你把它实现出来。但 AI 无法替你回答最关键的那一句:「这样做,真实用户会不会喜欢?」 只有走出去和人聊、看数据、看留存,才有答案。AI 很强,但产品是不是有人用,这件事永远只能从用户身上找证明。